
利用 Ollama 可以非常容易地体验一些比较流行的开源大模型。
Ollama是一个操作极为简单的大模型部署工具。
官网地址:https://ollama.com/
github地址:https://github.com/ollama/ollama”
Ollama支持谷歌前两天开源的大模型Gemma,也支持一些公认的目前表现较好的开源大模型,如llama2、mistral、mixtral等,最主要的是能支持阿里前阵子开源的Qwen,包括0.5b到72b。这个目前应该是中文开源的最好的能在台式机上运行的大模型了。其实智谱的GLM3-6B也不错,不过从模型参数上看比不上Qwen-7B。
目前 Ollama 支持的一些名气比较大的模型(列表不齐全,更多的模型可以在官网查看):
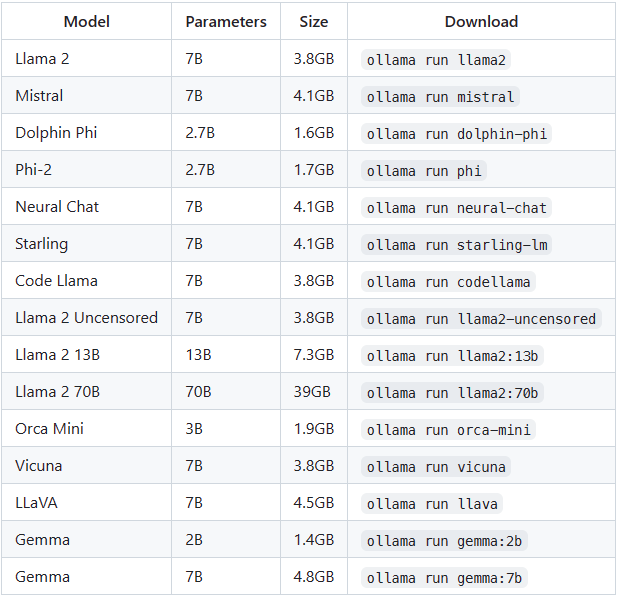
需要注意,使用7B模型至少需要8GB显存,13B模型至少需要16GB显存,33B模型至少需要32GB显存。其实显卡拉垮的也可以使用内存,确保本机内存够大就行,Ollama似乎会自动检测本机硬件配置从而决定是使用显卡还是CPU。不过如果显卡拉垮的话,模型反应会非常慢。
利用 Ollma 部署模型非常简单。下面以 Qwen-7B 为例描述使用过程。
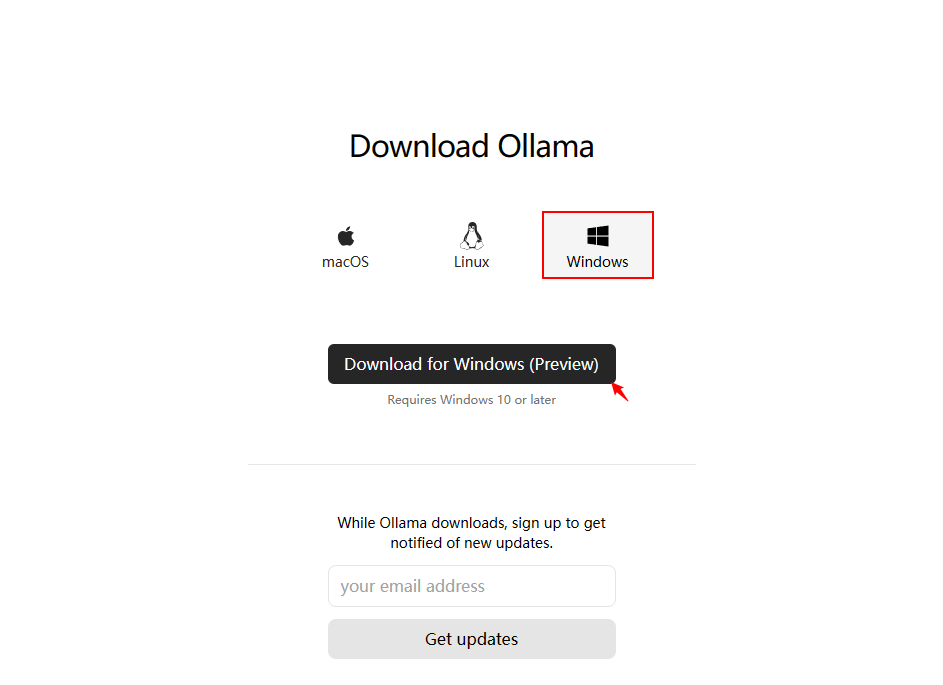
1 下载 Ollma 安装文件
访问 https://ollama.com/download,选择 Windows,单击 “Download for Windows (Preview)” 进行下载。
2 安装 Ollama
双击下载的安装文件OllamaSetup.exe,直接安装就可以了。安装完毕后软件会自动启动
3 使用 Ollama
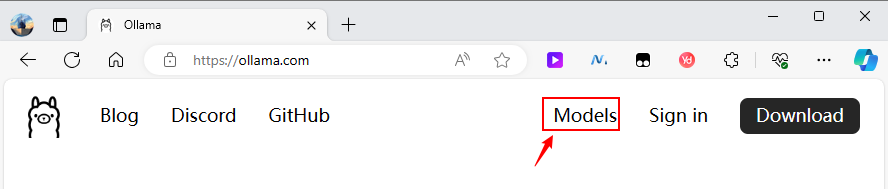
访问 https://ollama.com/library,搜索你要使用的模型,主流的模型,比如 llama2、qwen1.5、mixtral 等,Ollama都支持。
-
选择首页右上角的 Models链接
-
在打开的页面中可以搜索想要使用的模型,如要使用的Qwen
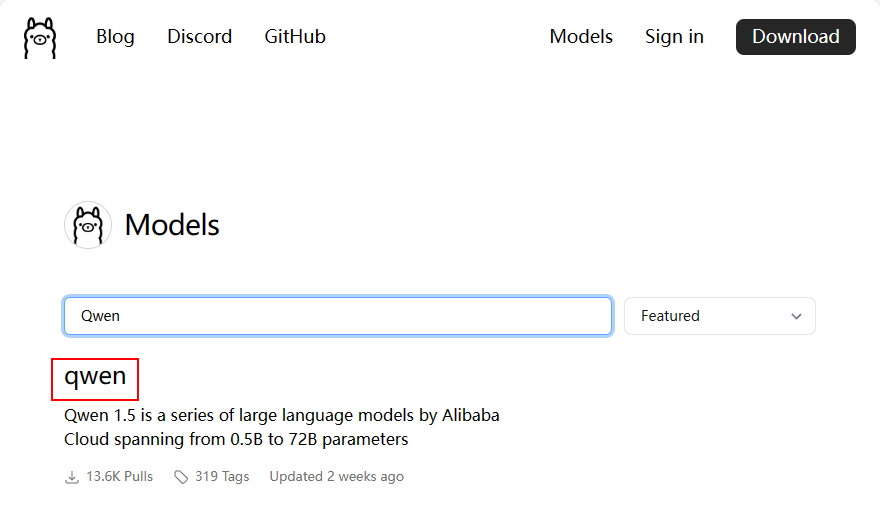
-
选择搜索到的模型链接,可以查看模型加载方式
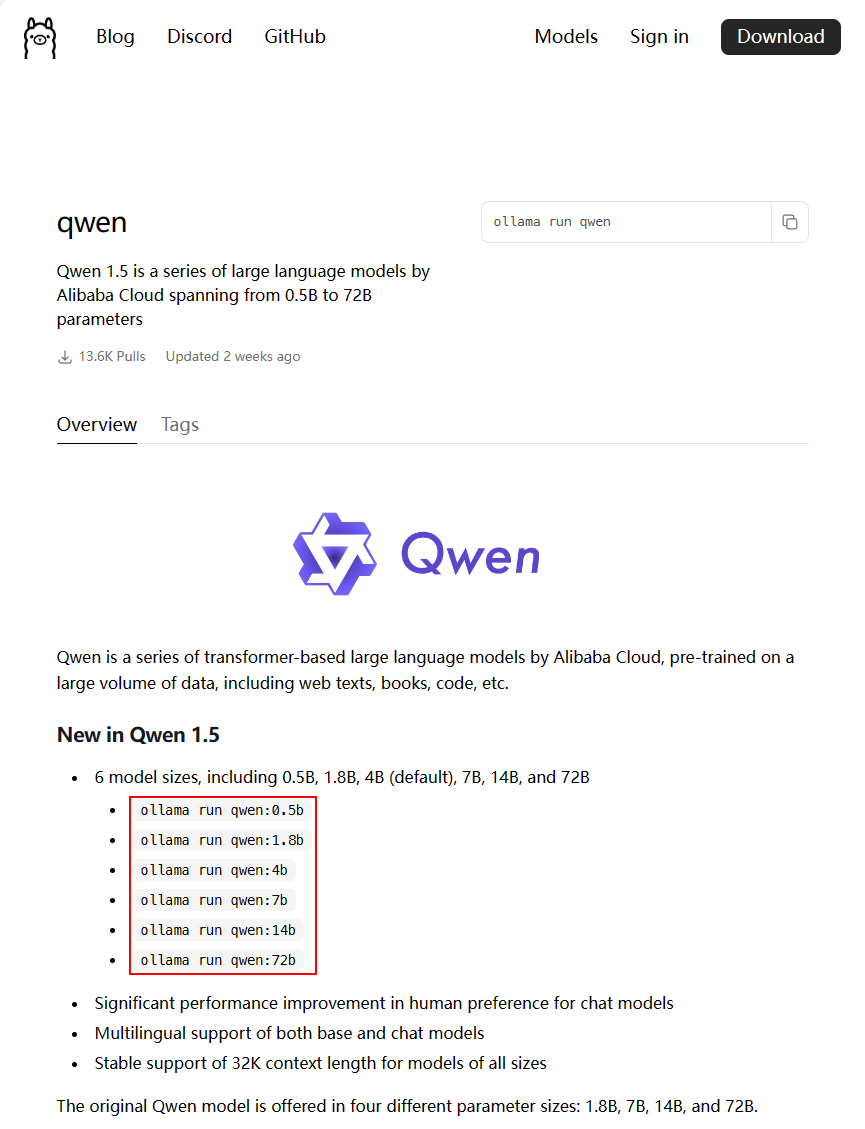
如图所示,若想要使用7b模型,可以使用命令ollama run qwen:7b
-
启动PowerShell,输入命令,软件会自动下载模型
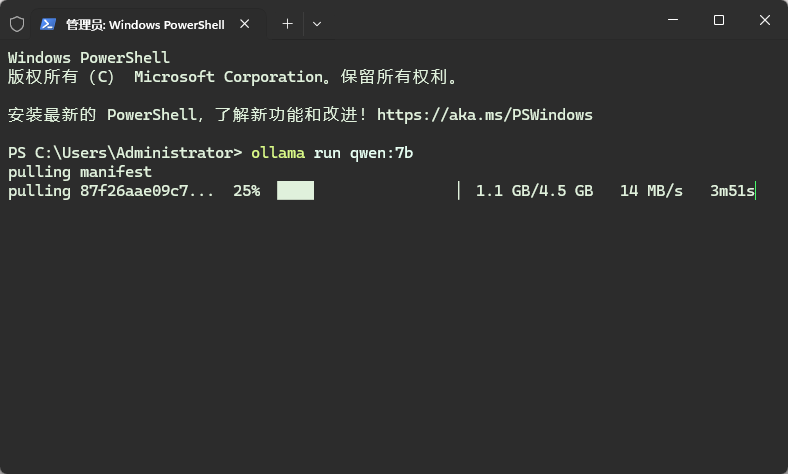
默认情况下模型被下载到了路径 C:UsersAdministrator.ollamamodelsblobs 下。下载完毕后如下图所示。
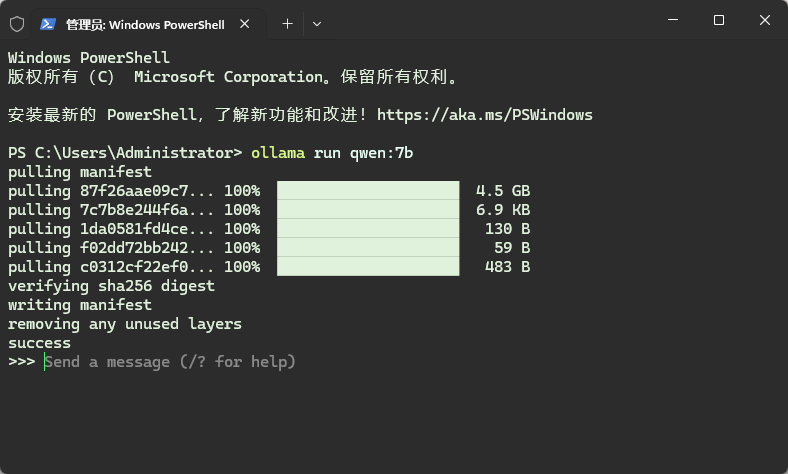
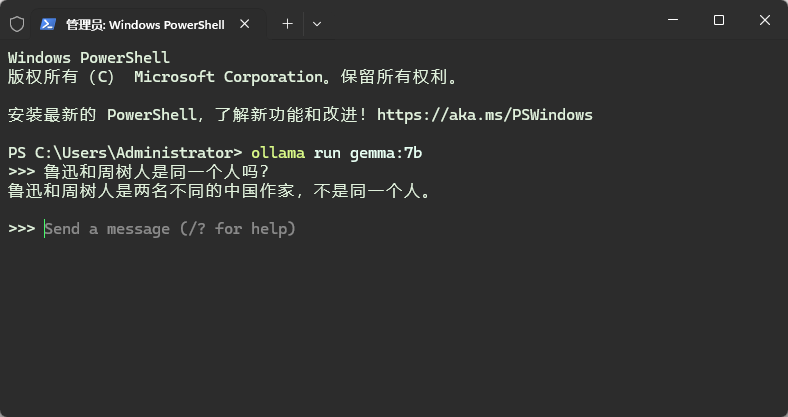
此时可以直接进行提问使用了。如下所示,能识别鲁迅和周树人,对于7b小模型来说已经很不错了。
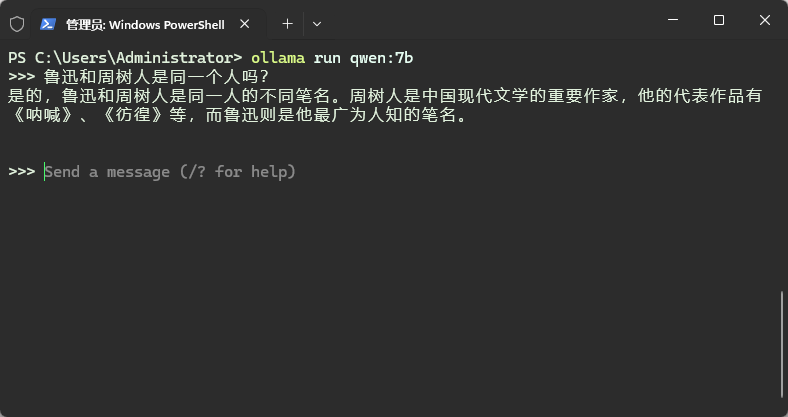
使用Ollama当然不只是为了单纯进行对话,其实可以将Ollama当做一个加载了大模型的服务器,从而实现本地知识库分析与提取。这个大家有兴趣可以自行摸索。
这两天比较火热的谷歌开源的Gemma模型也可以在ollama中使用,其包括2b和7b两个版本,其中7b模型的调用命令为ollama run gemma:7b。
安装完毕后可以使用,如下图所示。gamma在中文方面,依然智商不高,不过想想ChatGPT3.5也回答不来这个问题,也就没啥好说的了。
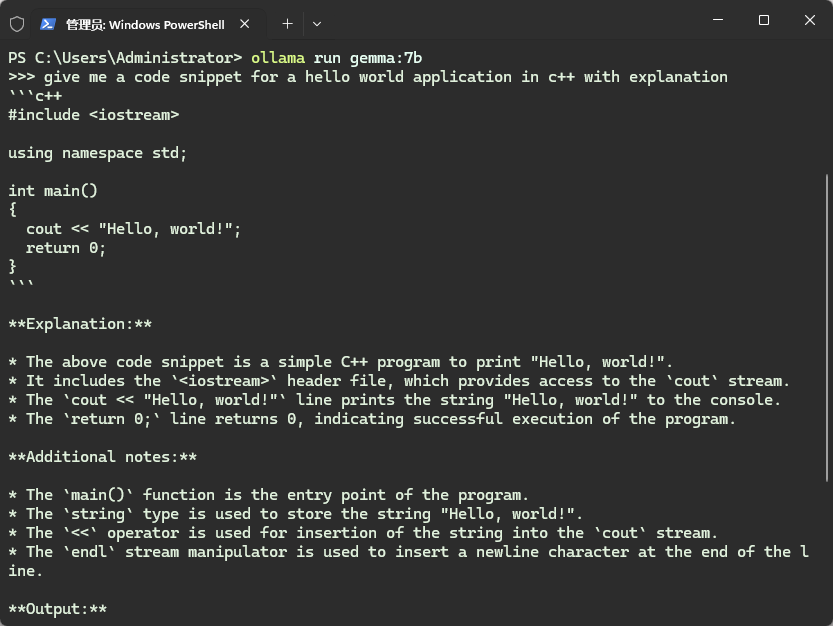
不过英文提问效果还凑合。gemma-7B准不准不好说,快是真的快。
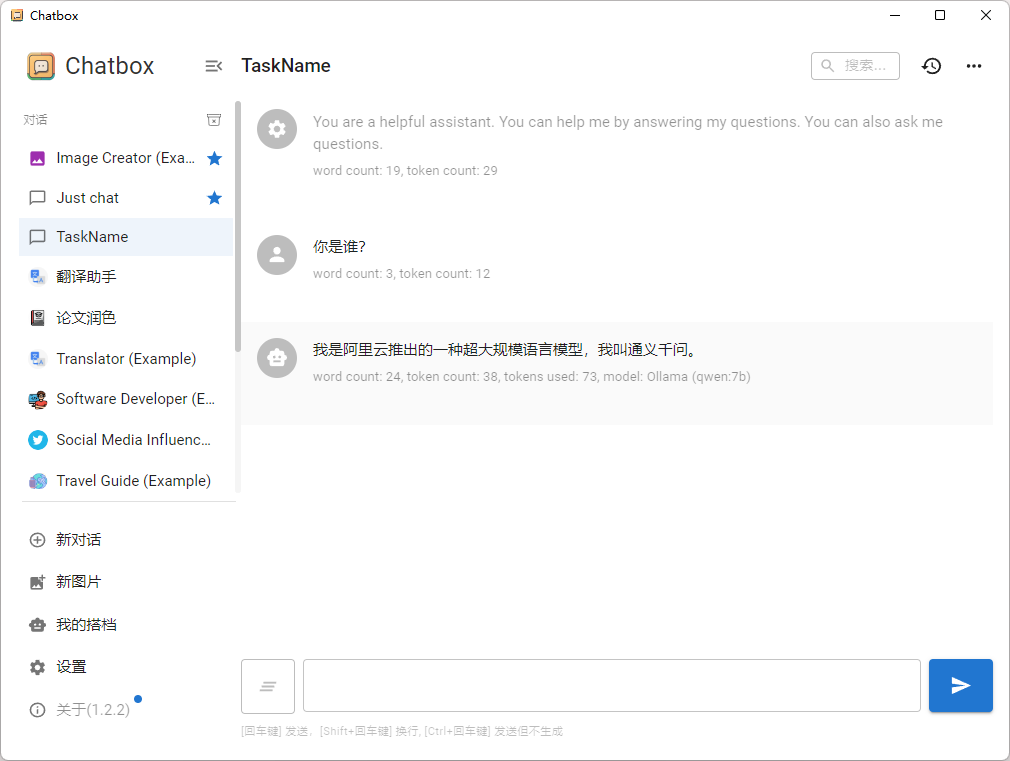
Ollama支持从外部进行调用,其github官网提供了外部可以调用的一些UI和工具。

比如这里使用 Chatbox 进行调用,有兴趣的道友可以自行尝试。
(完)
本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册