
话说com版的OpenFOAM也够惨的,先是被ESI收购,前阵子又被KeySight收购。开源软件想找条活路太难了。看看v2512版本都更新了些什么内容。
1 预处理
shortestPath 是一种线采样方法,接收两组点,并确定连接这两组点的任意“网格”路径。该方法通常用于网格调试,同时也被集成于 snappyHexMesh 网格生成器中。
本次版本更新纳入了 Robert Perry 提供的一项改进:在复杂并行场景下存在多条可行路径时,该改进能更准确地识别泄漏路径。
使用 sets 函数对象检测泄漏路径的典型输入如下:
leakFind
{
type sets;
writeControl timeStep;
interpolationScheme cell;
setFormat vtk;
// Needs at least one field
fields ( processorID );
sets
{
leakFind
{
type shortestPath;
insidePoints ((3.00013.00010.43));
outsidePoints ((101.3));
axis xyz;
}
}
}
2 数值方法
2.1 改进的梯度缓存
在现有梯度缓存功能基础上,本版本引入原位梯度更新机制,避免重复内存分配,从而降低梯度密集型仿真的计算开销。
梯度缓存配置位于 fvSchemes 文件中。用户可通过模式匹配启用全部梯度或特定变量的缓存,例如:
cache
{
"grad(.*)";
}
增强型缓存系统仅执行一次梯度存储空间分配,并在场变量值发生变化时就地更新缓存内容,在几乎无需额外配置的前提下显著提升运行性能。
演示案例位于 pitzDaily_fused 教程中。对该案例进行的性能测试显示逐步优化效果如下:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
用户可通过启用调试输出监控缓存行为:
DebugSwitches
{
solution 1;
}
调试输出通常包含以下信息:
-
Cache: Calculating and caching grad(U):正在分配并计算梯度; -
Cache: Reusing grad(U):找到与当前 U 场完全一致的已缓存 grad(U); -
Cache: Updating grad(U):找到已缓存的 grad(U),但 U 场已更新,需同步刷新缓存。
2.2 新增表达式模板
本版本首次引入表达式模板库,彻底改变场运算的执行方式。该强大优化技术可消除中间场变量的内存分配、将多个运算融合为单个计算核,并支持硬件加速(包括 GPU 卸载)。
基础功能作用于容器层级(Field),并进一步扩展至几何场层级(如 volScalarField、volVectorField 等)。一个典型应用是 fusedGauss 类梯度格式族。
需注意,当前功能尚未冻结,相关代码仍在持续开发中。以下为在 CPU 上对 volScalarField 表达式进行测试的结果:
-
简单表达式: c = a + b
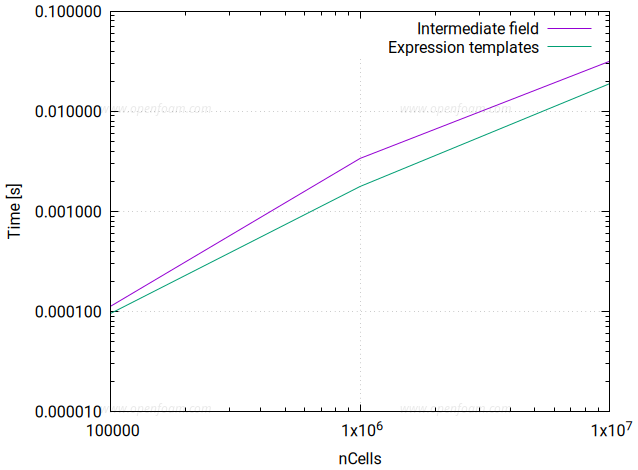
-
复杂表达式: c = cos(a + 0.5*sqrt(b-sin(a)))
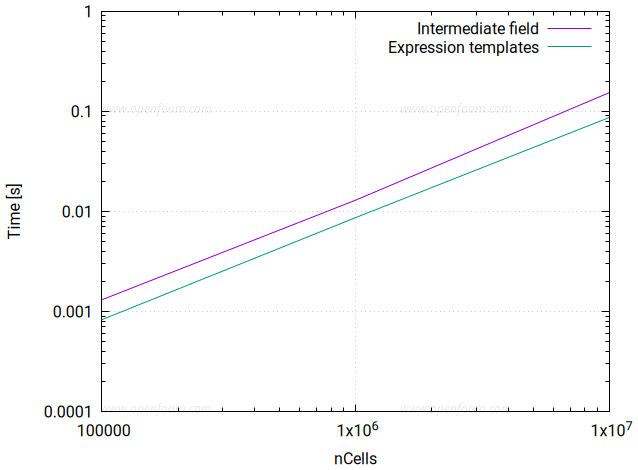
2.2.1 说明
几何场(geometric fields)的表达式求值分为三类独立计算:内部场、非耦合面片场(uncoupled patch fields)和耦合面片场(coupled patch fields)。AMD 提出的一项创新技术实现了融合面片求值(fused patch evaluation),即单个内核可同时处理全部非耦合(或全部耦合)面片,显著提升了边界面片数量较多时的计算性能。
2.2.2 应用场景
-
当前功能已在基础的 List和GeometricField上完成测试。 -
卸载(off-loading)功能已在 AMD 和 NVIDIA 主流统一内存架构上完成验证。 -
当前语法较为冗长;简化使用的相关工作正在进行中。 -
表达式模板(expression-templating)可应用于任意 GeometricField,例如表面场(surface fields)或有限面积场(finite-area fields)。 -
内部已实现不可压缩流动 kEpsilon 和 kOmega 湍流模型的对应版本,验证了现有模型向该框架迁移的可行性与便捷性。
2.3 AMI:新增缓存插值寻址与权重机制
任意网格插值(Arbitrary Mesh Interpolation, AMI)的插值模板(stencils)与权重现在支持缓存,有望显著提升动网格模拟(尤其是高核心数并行场景)的计算效率。
新引入的缓存机制通过复用已存储的信息,在 AMI 构建阶段避免了并行通信及模板组装过程。初步测试表明,在车轮旋转等外部空气动力学算例中,高核心数下可获得 10–30% 的加速比。
当采用固定时间步长,且完整旋转周期恰好被划分为整数个时间步时,系统可达到最优性能;此时直接重放缓存数据即可。否则,系统在相邻缓存实例之间实施线性插值。
缓存值按角度区间(angular bins)存储,其划分精度由边界面对应的 [optional] cacheSize 条目指定,该条目位于 polyMesh/boundary 文件中;例如,设置 1° 角度间隔的区间划分方式如下:
AMI1
{
type cyclicAMI;
AMIMethod faceAreaWeightAMI;
neighbourPatch AMI2;
...
// New optional entries
// Cache size: deactivated if not present/zero-sized
cacheSize 360;
// Always store a set of AMI data if the bin is empty
forceCache false;
// Maximum number of bins from current bin to search to construct
// the interpolation stencil. Default = 2
nThetaStencilMax 2;
}
2.4 GAMG:新增基于分解的粗化方法
GAMG 求解器新增的 decomposition 粗化方法,利用现有分解算法,为研究人员与高级用户提供更多灵活性,以探索多种多重网格粗化策略。
示例输入如下:
p
{
solver GAMG;
smoother GaussSeidel;
agglomerator decomposition;
decompositionCoeffs
{
numberOfSubdomains 8;
method scotch;
}
// Optional renumbering
// renumber true;
// Optional avoid enforcing connectedness of each coarse level
// forceConnected false;
interpolateCorrection true;
nCellsInCoarsestLevel 8;
...
}
通过调节 numberOfSubdomains 参数,用户可精确控制粗化层级,使其适配具体问题特征与计算需求。
当采用超过两级粗化时,通常建议启用二阶修正(interpolateCorrection true)。
需注意,该分解方法在启动阶段对每一级粗化网格均执行一次调用,因而增加整体计算开销。连通性强制步骤可能生成额外的粗化层网格单元,以维持区域连通性;但可通过将 forceConnected 设为 false 关闭此功能。用户还需注意,Scotch 等分解方法的行为可能随编译选项不同而呈现非确定性,导致连续多次运行结果存在差异。
2.5 社区贡献:GAMG——提升结果可重现性
此项改进涉及采用几何粗化(faceAreaPairGAMGAgglomeration)的模拟结果的可重现性问题。在某些硬件架构上,粗化过程在多次运行间可能出现差异。该现象源于采用 OpenMP 风格卸载机制时,粗化构建路径可能发生改变。初始粗化结构的任何变化,均会逐级传递至最粗层级,进而影响整体粗化结构,最终导致收敛行为出现差异;部分影响可通过收紧收敛容差予以缓解。
3 求解器与物理模型
3.1 湍流:kEpsilon 模型新增双层壁面处理方法
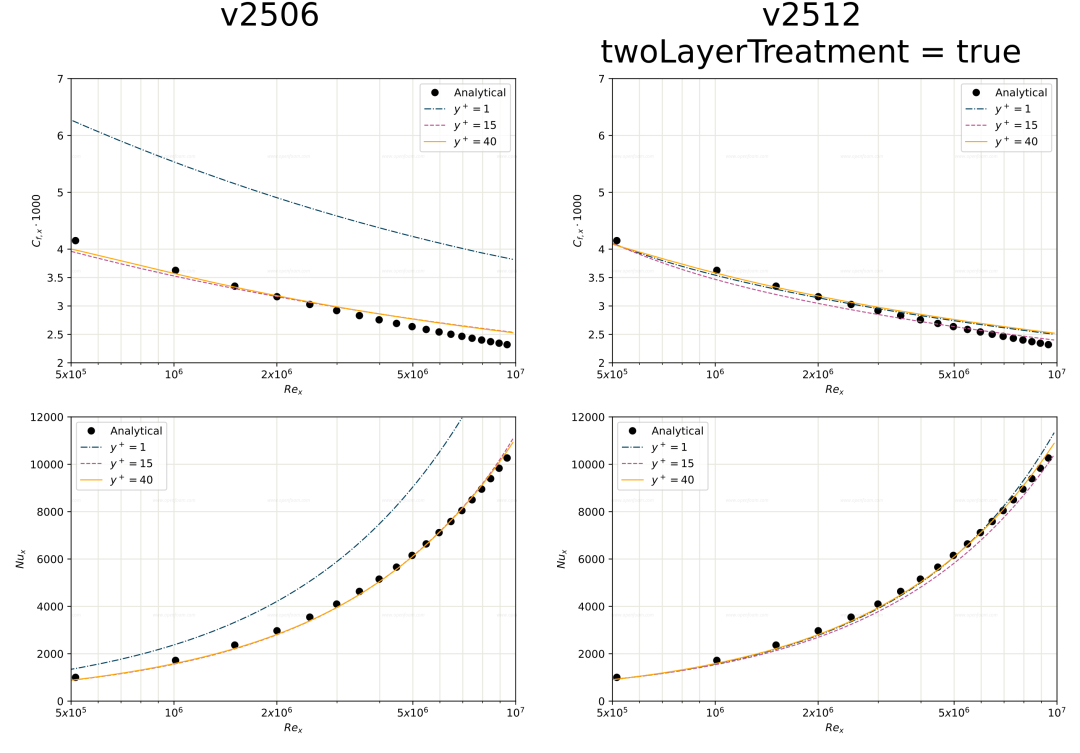
标准 k-epsilon 模型属于高雷诺数模型,因此在解析网格(例如 y+ < 11)下,其对壁面剪切应力与热流密度的预测结果不准确。为此引入一种双层壁面处理方法:在靠近壁面的内层区域,湍流粘度 νt 与湍流耗散率 ε 由代数关系式直接给出;而在外层区域,则仍采用标准 k-epsilon 模型求解。
该模型可通过可选标志 twoLayerTreatment 启用;默认状态下该标志处于关闭状态。
下图显示,在 y+ ∼ 1 的网格下,平板绕流算例的壁面摩擦系数与努塞尔数预测值偏高;而启用 twoLayerTreatment 标志后,网格敏感性显著降低。
3.2 有限面积法:新增分区动态接触角(zonal dynamicContactAngle)
有限面积(finite-area)框架已升级,支持基于区域的接触角设定,从而实现液膜表面空间变化的润湿特性建模。该功能使用户能够模拟接触角在不同区域存在差异的复杂场景,例如多材料表面或经化学处理的区域。
接触角从根本上影响液膜在固体表面上的铺展与演化行为,其作用机制在于改变接触线处的受力平衡计算。此前,用户仅能为每个有限面积表面指定单一接触角值,难以准确刻画非均匀润湿行为。
dynamicContactAngle 模型现已通过持久化场存储机制支持基于区域的定义,用户可借助 setFields 工具生成空间变化的接触角分布。
在液膜受力模型中配置基于区域的接触角:
// Mandatory entries
forces (dynamicContactAngle);
dynamicContactAngleCoeffs
{
// Mandatory entries
Ccf ;
// Optional entries
mode ;
hCrit ;
distribution ;
// Conditional entries
// Option-1: when 'mode' is 'zonal'
// 'dynamicContactAngleForce:theta' field can be set using 'setFields'
// utility. If there is no such field, a zero field is assigned
// to the entire finite-area surface, ie single zone. The units of
// the 'dynamicContactAngleForce:theta' field is [deg].
// Option-2: when 'mode' is 'filmSpeed'
Utheta >;
// Option-3: when 'mode' is 'filmTemperature'
Ttheta >;
}
3.3 有限面积方法:新增浸没边界法(IBM)
本次发布在有限面积(FA)库中新增了浸没边界法(IBM)功能,从而在无需边界贴体网格的前提下,更灵活地模拟薄液膜与复杂几何体之间的相互作用。
该模型以全新的 regionFaModel 形式实现,并通过在速度边界场配置中选择 kinematicThinFilmIBM 变体予以启用;例如,在新增的挡风玻璃(windshield)教学案例中,采用如下 U 边界条件:
myPatch
{
type velocityFilmShell;
...
region film;
// New model: kinematicThinFilmIBM
liquidFilmModel kinematicThinFilmIBM;
}
该设置需配套一个
IBM1
{
surface "/surface1.obj" ;
solidBodyMotionFunction ...;
// Motion properties for body IBM1
...
}
IBM2
{
surface "/surface2.obj" ;
solidBodyMotionFunction ...;
// Motion properties for body IBM2
...
}
每个障碍物由一个封闭曲面几何文件表示,其运动可通过 solidBodyMotionFunction 进行设定。
4 后处理
4.1 函数对象:增强版 mapFields 功能
mapFields 函数对象已扩展,支持处理移动网格情形。
典型输入字典示例如下:
{
// Mandatory entries
type mapFields;
libs (fieldFunctionObjects);
mapRegion myTetMesh;
mapMethod cellVolumeWeight;
consistent yes;
fields (U); // ("U.*" "p.*");
}
注意:在上述示例中,目标网格(mapRegion)已通过 cellDecomposer functionObject 单独生成(该工具可将网格单元分解为四面体)。
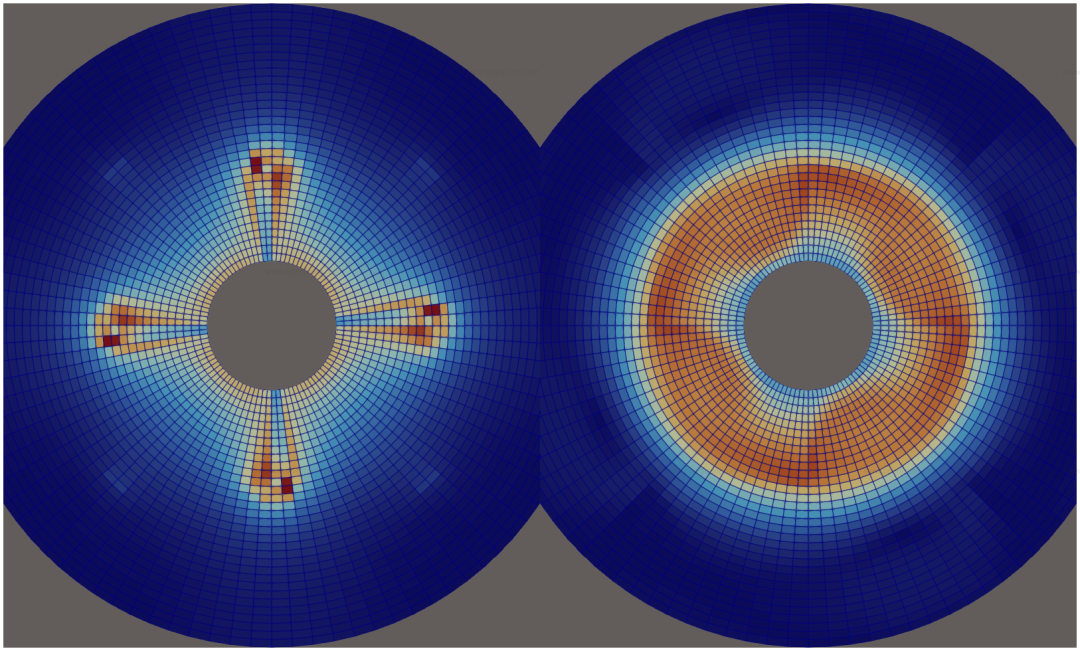
下图展示了将速度场从(运动的)mixerVesselAMI2D 教程映射至静态网格后的结果。
4.2 函数对象:改进的 wallHeatFlux 及新增的热流计模型
热流计是实验装置壁面上安装的物理测量设备。多数热流计采用水冷方式,因此其温度与周围壁面温度不同。
此前,模拟此类仪器需在每个热流计安装位置单独创建小型专用面片(patch),以便 OpenFOAM 的 wallHeatFlux 函数对象进行处理,这增加了网格生成和算例设置的复杂性。
新增的 gauge 壁面热流后处理模型可在不创建独立面片的前提下,计算通过热流计的对流与辐射热流。用户可在指定位置配置多个热流计,并为其设定温度、吸收率及发射率等可调参数。输出结果以独立文件形式分别提供对流热流、辐射热流及总热流的预测值。
此外,对 wallHeatFlux 函数对象进行了进一步重构,为未来接入更多可插拔式热流模型预留了接口。需注意,本次更新完全兼容现有 wallHeatFlux 配置。以下为 gauge 模型的最小化使用示例:
FOwallHeatFlux
{
// Mandatory entries
type wallHeatFlux;
libs (fieldFunctionObjects);
model gauge; // or 'wall' for the existing wallHeatFlux model
Tgauge ;
patch ;
// Optional entries
absorptivity ;
emissivity ;
T ;
qin ;
alphat ;
convective <bool>;
radiative <bool>;
writeFields <bool>;
// Inherited entries
...
}
4.3 函数对象:新增radiometer探针模型
radiometerProbes 函数对象支持在计算域内任意位置监测入射辐射热流。该功能将辐射分析能力从边界表面拓展至域内空间,适用于辐射传感器布点研究及内部热环境评估等应用场景。
此前,入射辐射热流(qin)的计算仅限于边界面片(boundary patch)的面元,导致分析范围局限于表面位置。对于需要获取域内点辐射数据的工程师与研究人员,此前缺乏直接采样机制。新函数对象通过调用 OpenFOAM 的 probes 采样基础设施,在用户指定的域内位置实现定向入射辐射的捕获,从而弥补了这一空白。
以下为 radiometerProbes 函数对象的最小化示例:
radiometer
{
// 必需条目
type radiometerProbes;
libs (utilityFunctionObjects);
probeLocations ();
probeNormals ();
// 继承的条目
...
}
5 基础设施
5.1 内存:新增 PatchF5.1 场函数,避免内存分配
此项增强是持续提升 OpenFOAM 在现代计算架构上性能工作的一部分。在当前处理器上,缓存效率与内存带宽已成为关键性能因素,内存分配开销因而日益显著。
首先,面片(patch)场函数现以结果缓冲区作为输入参数,不再返回临时字段。例如,patchNeighbourField(UList 替代了 tmp。
其次,GeometricField 对象的内部存储部分现继承自 DynamicField,而非 Field,从而自动支持超出可寻址尺寸的存储容量。额外存储仅分配一次,并随物理场长期存在;其用途是提供一个供 API 调用填充的暂存区(scratchpad),其中索引方式对内部值与获取的边界值保持一致。当暂存区未被使用时,该机制仅引入极低开销(单个 label)。
这些扩展已应用于 fused 离散化方法中,大幅减少对 fvPatchFields 的操作所引发的内存分配,并显著简化面向卸载(offloading)目的的基于单元(cell-based)循环实现。
5.2 内存:内存池
作为支持现代架构工作的组成部分,OpenFOAM 的 List 和 Field 容器现已支持使用 Umpire memory management。
内存池尤其适用于 GPU 系统及配备高带宽内存的系统。
当 OpenFOAM 编译时启用了 Umpire,其启用状态可通过环境变量 FOAM_MEMORY_POOL 或优化开关 memory_pool 控制。当前支持选择 host、device 或 managed(统一内存)三种内存池类型,并可配置相应尺寸与增量参数。
内存池接口保持不透明设计,这意味着可在现有安装基础上,仅通过极小范围的重新编译(OS-specific)和重新链接(OpenFOAM),即可添加内存池支持。
5.3 VTK:OpenFOAM/VTK 基础设施更新
为提前适配未来对新型 VTKHDF 数据格式的支持,基础设施调整工作已启动。除并行基础设施(如 globalOffset)的更新外,非结构化(体)网格的内部簿记机制现已支持全局寻址空间,作为当前基于流(stream-based)格式的替代方案。随着 VTKHDF 格式持续演进并逐步确立为新标准,后续版本还将推出更多相关功能。
6 可用性
6.1 ParaView:改进的读取器模块
OpenFOAM 面向 ParaView 的附加读取器模块(paraFoam)已更新,以支持新型多区域有限面积(multi-area finite-area)框架。作为更新后的有限面积框架的一部分,面积场(area fields)现与体积场(volume fields)和点场(point fields)分离注册。这一变化已在读取器模块中体现为新增的“面积场”选择项:
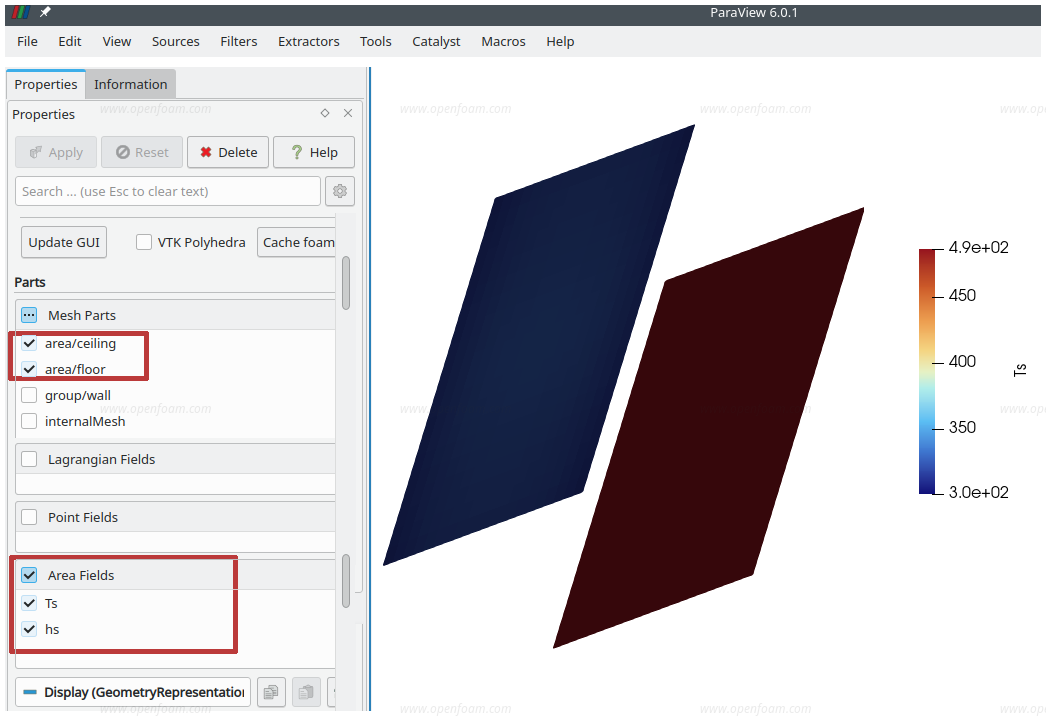
ParaView 的 blockMeshDict 读取器模块(paraFoam -block)已更新,支持多区域解析。对于 blockMesh,点坐标现在保持与 OpenFOAM 相同的数值精度(单精度 float 或双精度 double)。
6.2 代码仓库:GitLab 迁移已顺利完成!
OpenFOAM 代码仓库向 GitLab 的迁移现已全部完成!继 v2506 版本发布公告之后,所有核心 OpenFOAM 仓库均已成功从旧平台 https://develop.openfoam.com 迁移至新地址:https://gitlab.com/openfoam。
所有核心 OpenFOAM 仓库现均可通过 https://gitlab.com/openfoam/core/openfoam 访问。用户可注册 GitLab 账户,以访问代码仓库、提交问题报告(issues)并发起合并请求(merge requests)。
此次迁移是推动社区协作的重要一步。GitLab 平台提供了更完善的版本控制、合并请求及代码审查工作流工具,使全球贡献者更便捷地参与 OpenFOAM 的开发工作。
如需开始使用新的仓库地址,请更新本地远程 URL;若计划参与贡献,还需注册 GitLab 账户。由于账户命名冲突,此前平台的用户关联信息未能完全迁移;但创建新的 GitLab 账户操作简便,注册后即可立即使用全部仓库功能。
欢迎社区持续贡献——自迁移完成以来,已接收并处理了多项合并请求!这种协作模式进一步巩固了 OpenFOAM 作为领先开源计算流体力学(CFD)平台的地位。
7 并行计算
7.1 合并式 I/O
用于处理合并格式(collated format)的代码已完成更新与优化。本次修改旨在降低数据传输过程中的内存开销,并减少各进程(ranks)之间的并行协调(同步点)。对于非合并格式的主控进程(master-only)写入模式,系统现采用轮询调度(polling dispatch)机制,在文件内容就绪时立即执行写入。
除原有合并格式写入功能外,本版本还新增支持基于 MPI-IO 的后端实现,用于生成合并格式文件。所生成的文件完全向后兼容现有及以往所有版本的该格式,即:可使用 MPI-IO 创建合并文件,并由旧版 OpenFOAM 正常读取。
对于单次使用场景,用户可通过 collated backend 优化开关进行选择,例如:
mpirun -np NN redistributePar
-decompose -parallel
-fileHandler collated -opt-switch collated.backend=1
如需长期启用该功能,可在 etc/controlDict 中相应条目进行配置。
7.2 OffsetRange与GlobalOffset
新增的 OffsetRange 和 globalOffset 容器,以极低的内存与通信开销简化全局寻址问题。二者均为轻量级集合,仅存储起始位置(start)、尺寸(size)和总量(total)三类信息,但语义上支持所谓 块(slab) 或 超块(hyperslab) 寻址方式。
示例用法如下:
globalOffset cellSlab = mesh.nCells();
globalOffset pointSlab = mesh.nPoints();
globalOffset faceSlab = mesh.nFaces();
Foam::reduceOffsets(comm, cellSlab, pointSlab, faceSlab);
Info<< "nCells:" << cellSlab.total() << nl;
// OR
List slabs = ...;
Foam::reduceOffsets(comm, slabs);
7.3 MPI 内建函数
本版本对 Pstream 库进行了若干小幅但实用的改进。该库作为 MPI 的中间接口层,实现了高层代码与特定 MPI 版本及厂商的解耦。
7.3.1 扫描与排他扫描
Pstream 类现已提供对 MPI_Scan 和 MPI_Exscan(排他扫描)函数的接口支持,此前这些函数未被覆盖。尽管此前并未明显缺失此类功能,但排他扫描(以求和为例)提供了一种特别实用且可扩展的方法,用于生成全局一致的偏移量,其通信开销低于当前 globalIndex 所需的开销。
7.3.2 广播
本版本扩展了广播功能,支持以任意处理器秩(rank)作为根节点,广播任意秩的原始数据。该能力支持协调式算法,使不同处理器秩可轮流担任主控角色并分发数据。
7.3.3 find_first、find_last
新增的 UPstream::find_first() 和 UPstream::find_last() 方法为不同处理器秩之间的控制协调提供了便捷且低开销的手段。一种典型用法示例如下:
// Find the first rank with a valid reference point
label refCelli = mesh.findCell(, ...);
label ranking = UPstream::find_first((refCelli >= 0), communicator);
if (ranking < 0)
{
// Nobody found it - try something else
...
}
// Lowest rank takes the lead
if (ranking != UPstream::myProcNo(communicator))
{
refCelli = -1;
}
该示例还可进一步扩展,用于决定是否向其他处理器秩广播相关信息。
7.3.4 reduceOffset、reduceOffsets
新增的 Foam::reduceOffset() 和 Foam::reduceOffsets() 函数旨在解决在最小化内存与通信开销的前提下定义全局一致偏移量范围的问题。它们利用新引入的 Exscan 函数确定各处理器秩专属的偏移量,并结合更新后的广播方法将总尺寸信息同步至所有处理器。
相较于现有的 globalIndex,该新方案以 Exscan 加广播替代了 MPI 的 Allgather 通信模式,从而提升了可扩展性。此外,用户还可通过 reduceOffsets() 函数批量计算多组偏移量。该函数将全部数值合并后统一通信,因此仍仅需恰好两次 MPI 函数调用。
8 插件
8.1 新插件:研究资源库
我们很高兴宣布,在 plugins 子模块下新增一个资源库:Research。
新设立的 Research 资源库旨在作为共享实验性与研究性 OpenFOAM 开发成果的平台,这些成果具有 not yet part of the main OpenFOAM release 特性。它为尚未完成、高度实验性、面向特定领域或尚不具备纳入核心发行版条件的工作提供了一个 staging area;同时,这些工作对用户与研究人员仍具潜在价值,并可作为开发同类定制化应用的参考范例。
该资源库中的内容按 as-is 方式提供:不保证稳定性、向后兼容性或长期支持;API、名称及行为可能随时变更(包括组件移除),且不另行通知。
每项开发均自成一体,通常包含 code、位于 README.md 或 .pdf 中的文档说明,以及可选的 test 算例。
该资源库的初始模型及相关全部细节详见以下链接:
|
|
|
|
|---|---|---|
redistributedResistivityAlgorithm |
|
|
FastRK |
|
|
PRECISE |
|
PISO 的 pressure-velocity 耦合算法 |
HelicalForce |
|
|
8.2 重分布电阻率算法
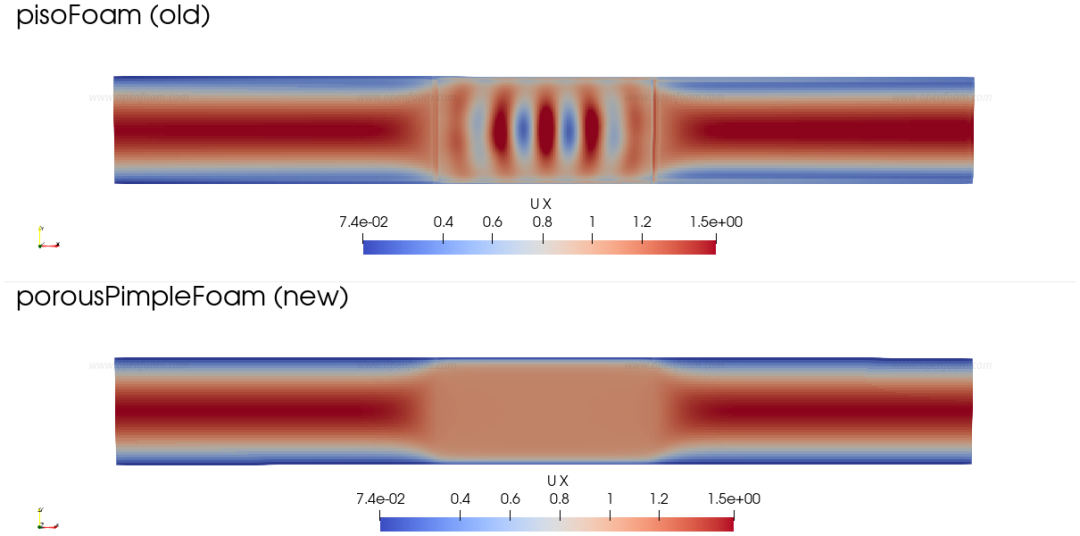
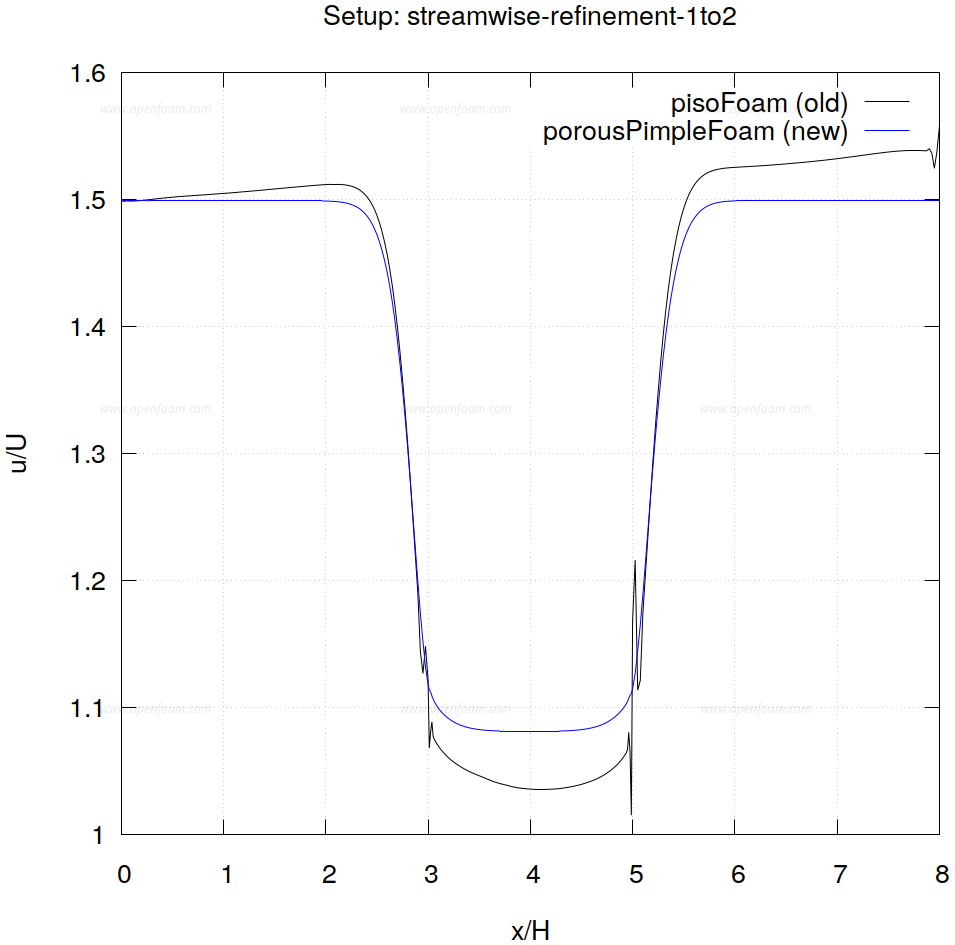
在单相流体宏观尺度多孔介质建模的计算流体力学方法中,流体–多孔介质界面附近常难以获得物理上合理的数值解。若未对算法进行专门设计,界面处材料属性(尤其是多孔介质阻力系数)的不连续性将导致解出现非物理振荡。
为避免流体域与多孔域之间尖锐界面附近的虚假振荡,Nordlund et al. (2016) 提出的重分布电阻率(RDR)算法是一种有效方案:该算法对原始 PISO 算法和 Rhie-Chow 插值方法进行改进,并在 PISO 预测步之前引入额外步骤,将多孔阻力重新分配至界面邻近网格单元。为避免高雷诺数、低达西数流动中因显式处理引起的时步限制,相关建模项采用隐式处理。
以下展示标准 PISO 算法与 RDR 算法在流体–多孔界面处采用流向 1:2 网格加密时的对比测试结果(更多测试案例及完整细节参见 redistributedResistivityAlgorithm::README.pdf):

8.3 快速龙格–库塔法
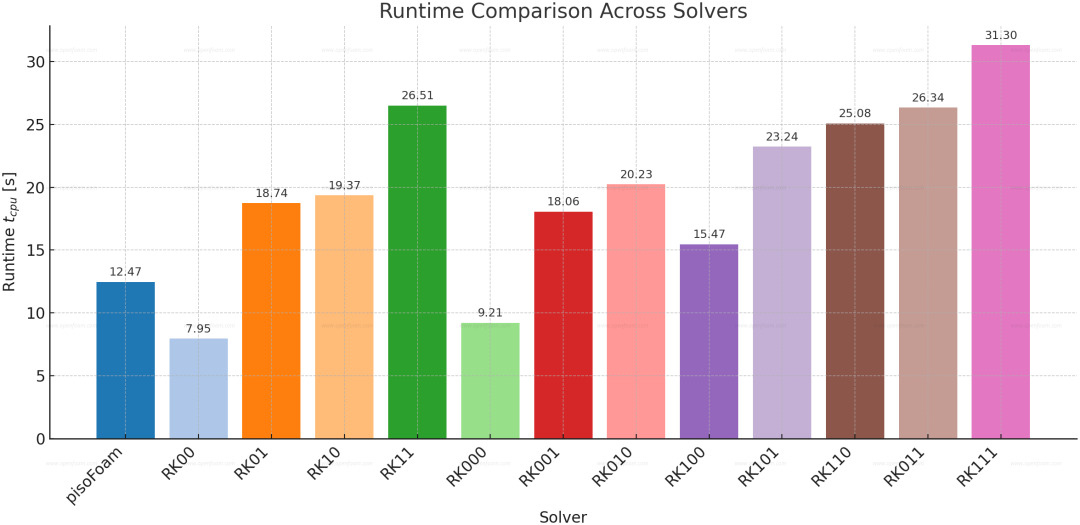
在采用 DES/LES 方法开展高度非定常模拟时,类 SIMPLE 的压力–速度耦合算法被证实计算耗时较长。
另一类压力–速度耦合算法——分数步(投影)算法——由此受到关注。研究表明,相较于类 SIMPLE 算法,分数步算法在大规模非定常模拟中具有更优的计算成本特性。
一种名为 FastRK 的有前景方法已由 Karam & Saad (2023) 实现:该算法族基于速度场的亥姆霍兹分解,将其分解为无散(散度为零)和无旋(旋度为零)两个分量。该方法通过首先计算一个未必满足不可压缩性约束的中间速度场,再通过投影步骤强制施加该约束,从而实现压力与速度的耦合。
以二维泰勒-格林涡问题为例,以下为各求解器所获得的模拟 CPU 时间结果(更多测试及完整细节参见 FastRK::README.pdf):
|
|
tcp**u
|
pisoFoam 的差值 |
|---|---|---|
pisoFoam |
|
|
RK00 |
|
|
RK01 |
|
|
RK10 |
|
|
RK11 |
|
|
RK000 |
|
|
RK001 |
|
|
RK010 |
|
|
RK100 |
|
|
RK101 |
|
|
RK110 |
|
|
RK011 |
|
|
RK111 |
|
|
8.4 PRECISE 算法
在同位网格有限体积法应用中,PISO 算法表现出对时间步长和松弛因子的依赖性,这一现象主要归因于 Rhie-Chow 插值方法。
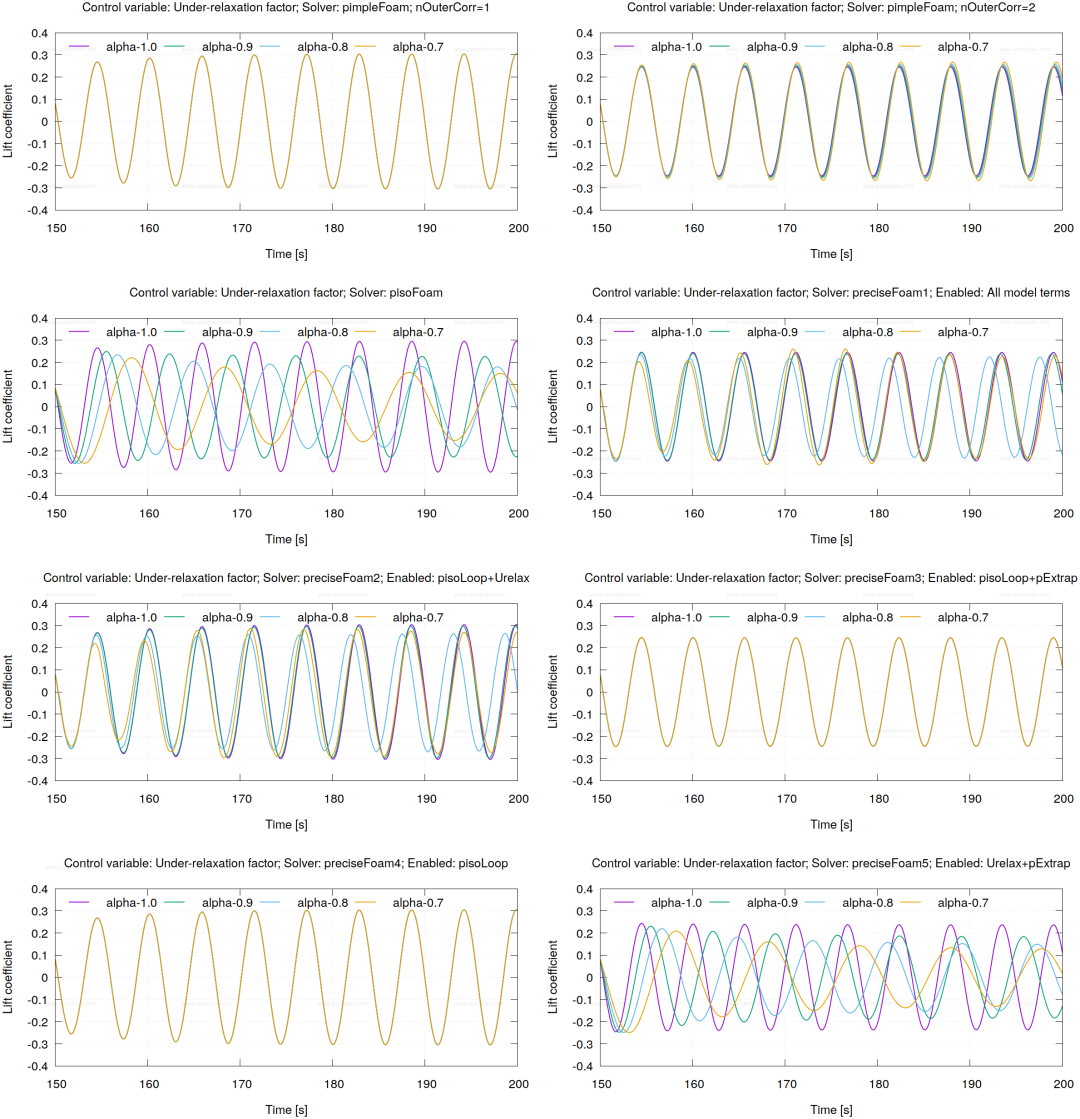
现有方法中一种颇具前景的改进方案是 Ammad et al. (2024) 提出的“PRECISE”算法(即采用一致 Rhie-Chow 插值与二阶外推的 PISO 算法)。该算法宣称已缓解 PISO 算法对时间步长与松弛因子的依赖性,并通过引入二阶插值单元进一步提升了算法稳定性。
下图展示了原始测试案例及其在不同欠松弛因子与时间步长下的若干对照研究结果(更多测试及完整细节参见 PRECISE::README.pdf)。
各求解器在不同欠松弛因子下对升力系数结果的影响对比
原文地址:https://www.openfoam.com/news/main-news/openfoam-v2512。本文为简易AI翻译,有疑问可以查看原文。
”
(完)

本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册