
前面有提到说借助大语言模型将Fluent的用户文档和理论文档给机翻了一遍(见Fluent理论文档中文版V1及Fluent UserGuide中文版)。后台有道友问使用了哪些大模型。基于好东西不能藏私的指导思想,这里就来逐个介绍一下。
1 文档本地化
第一步工作是将文档转化为本地markdown格式。这里有两种方式:
-
数学公式非常多的文档。比如Theory Guide,里面有大量的数学公式需要转化成latex格式,一个个的识别肯定不太现实。这里使用的是 Doc2x(官网地址:https://doc2x.noedgeai.com/),不过这货现在收费了,1000页文档需要11块。公式识别效果还不错,不过对于文本格式(如加粗、斜体等)的识别效果不佳。非常适合于大量公式需要处理的文档。如果不想花钱,开源的话也可以选择使用Marker(地址:https://github.com/VikParuchuri/marker)、MinerU(地址:https://github.com/opendatalab/MinerU)或pymupdf4llm(官网地址:https://pypi.org/project/pymupdf4llm/)等。不过开源程序在应付复杂文档时可能会效果不佳。 -
文本格式比较多的文档。如User Guide。文档中包含有大量的格式样式(加粗、斜体、缩进、列表、表格等)。这类文档使用上面的工具效果都很差。一般情况下可以打开网页版,然后直接将页面内容拷贝到markdown编辑器(如typora、obsidian等)中,可以完整保留原文格式。
2 文档翻译及润色
现阶段我使用的是大语言模型进行翻译。主要是考虑专业术语翻译和后期的文本润色。目前大语言模型对专业术语的识别效果还是挺不错的,而且可以读取整段文本进行翻译,这与传统的逐句翻译模式不同。
目前主要使用的是国产大模型qwen2.5-72B与deepseek。其中qwen2.5-72B主要用于翻译,而deepseek则主要用于润色,总体上来看效果还是挺不错的。使用过程中个人感觉就翻译效果来说千问商业大模型(包括turbo、pro和max版)实际效果远不如其开源的72B版本,而deepseek的中文表达能力个人觉得相当好,很符合本人的语言表达习惯。
qwen2.5-72B与deepseek均使用的是硅基流动(地址:https://siliconflow.cn/zh-cn/)提供的api。
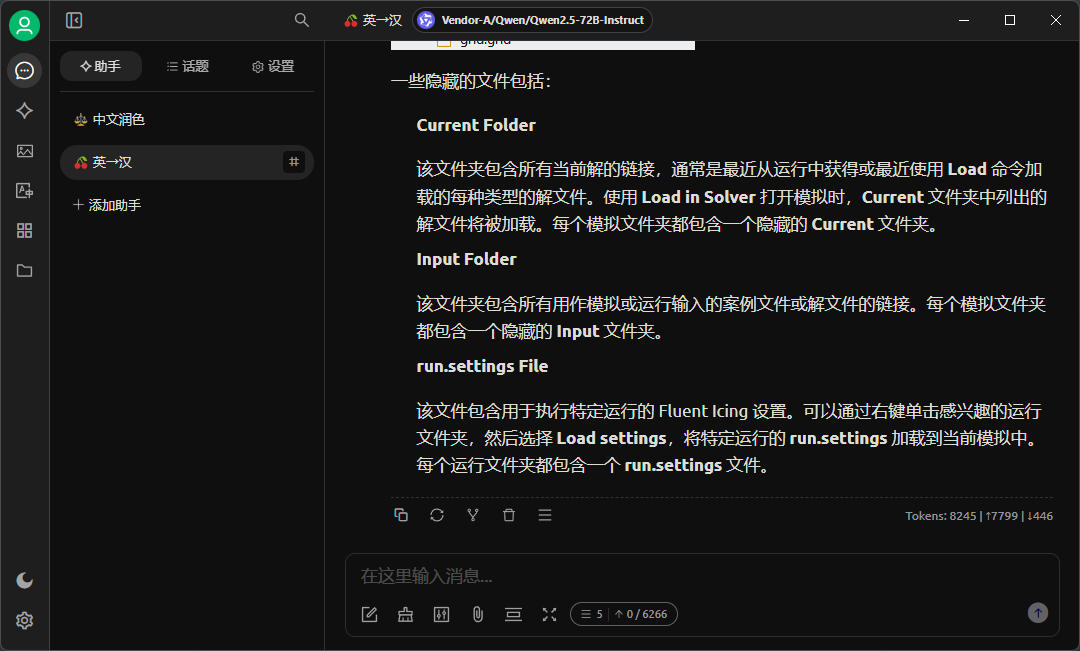
为了方便,在使用过程中还用到了一个名为Cherry Studio(地址:https://cherry-ai.com/)的前端工具,此工具支持定义智能体,因此只需要将智能体定义后,后续就能够将待翻译的markdown文件扔进去自行翻译和润色了。
3 文档校对
这个目前没有那么好的工具,只能靠人工了。
(完)
本篇文章来源于微信公众号: CFD之道






评论前必须登录!
注册