
最近尝试使用STAR CCM+的GPU计算,发现计算效率提升还是比较明显的,尤其是对于一些规模不大,能够以全GPU模式运行的仿真计算。而且STAR CCM+对显卡的支持似乎也挺友好,普通游戏卡也能参与。
下面是文档中关于GPU计算的一些关键信息。
1 支持的硬件
启用 GPGPU 的仿真支持 NVIDIA 和 AMD 的特定显卡型号。鉴于 GDDR(图形双倍数据速率)内存带宽往往难以满足 CFD 应用需求,优先选用配备 HBM(高带宽内存)的型号。
推荐选用基于 NVIDIA Volta、Turing、Ampere、Hopper、Ada Lovelace 及 Blackwell 架构的显卡。需配备 CUDA 12.2 或更高版本的驱动(即 CUDA 驱动版本 535.104.05 及以上)。不支持利用 NVIDIA Multi-Instance GPU (MIG) 进行硬件分区。
服务器推荐选用 AMD Instinct MI100、MI200 及 MI300/MI350 系列显卡。需注意,MI300/MI350 系列可能无法发挥最佳性能。此外,Instinct 系列不支持 Windows 系统。
推荐在工作站中使用 AMD Radeon PRO W6800、V620、W7800、W7900 以及 Radeon AI PRO R9700。Linux 系统需采用 AMDGPU 驱动,不支持 AMDGPU-PRO 驱动。Radeon AI PRO R9700 暂不兼容 Windows 系统。
同时支持集成于 AMD Ryzen AI MAX 系列(Strix Halo 架构)CPU 中的 AMD Radeon 8000S 系列 GPU。为最大限度释放内存用于 GPGPU 计算,建议将 BIOS 中的显存大小配置为最小值。
当前所有 AMD GPU 均需在内存容量与整体性能之间进行权衡,其影响程度因型号而异,在 MI300A 及 Windows 系统上尤为显著。Simcenter STAR-CCM+ 默认在所有 GPU 上优先保障更高内存容量,但在 MI300A 和 Windows 系统上例外,这两种情况优先追求性能。如需调整此默认行为,可通过设置环境变量 HIP_MEM_POOL_SUPPORT=0 以获取更高内存容量,或设置 HIP_MEM_POOL_SUPPORT=1 以追求更高性能。
若在 AMD GPU 上遭遇卡顿,且内核日志(dmesg)显示类似 [drm:amdgpu_job_timedout [amdgpu]] *ERROR* ring sdma0 timeout 的错误信息,请设置环境变量 HSA_ENABLE_SDMA=0。
2 遵循的基本原则
使用 GPGPU 运行 STAR-CCM+ 仿真时,需在启动服务器时激活该选项。通常情况下,分配的 CPU 核心数应至少与计划使用的 GPGPU 卡数量相同。另外在使用GPGPU计算之前,需确保 GPGPU 硬件受 STAR-CCM+ 支持。
使用GPGPU计算需遵循以下的一般原则:
-
在采用代数多重网格 (AMG) 的仿真中使用 GPGPU 时,建议避免将 Cycle Type 设置为 F Cycle 或 W Cycle ,以免降低性能。 -
为实现最佳性能,需为 GPGPU 分配合理的工作负载,在确保高占用率的同时不超出内存限制。对于单精度运行的切割体网格,典型估算值为每 1,000,000 个网格占用 1.3 GB GPGPU 内存。 -
当仿真计算超出 GPGPU 内存限制时,系统未必会生成明确的错误提示,因此操作需谨慎。在 Windows 系统中,GPGPU 内存可能溢出至系统内存,错误消息甚至可能完全缺失。此时仿真虽会继续运行,但性能将严重下降。 -
可通过创建 GPGPU Resident Memory Report 来监控仿真运行期间的 GPGPU 内存使用情况。 -
CPU 进程数必须至少等于主机上选用的 GPGPU 卡数量;否则,实际使用的 GPGPU 数量将受限于分配的 CPU 进程数。 -
部分 GPGPU 卡包含多个逻辑 GPGPU。就 STAR-CCM+ 而言,每个逻辑 GPGPU 均被视为独立的 GPGPU 卡。 -
若仿真中的所有操作均启用 GPGPU,分配的 CPU 数量应与 GPGPU 卡数量一致,以避免因 GPGPU 超额订阅而导致性能损失。 -
若部分操作在 CPU 上运行,建议分配的 CPU 数量多于 GPGPU 卡数量,以避免性能下降。此时,宜将 CPU 进程数设置为所用 GPGPU 卡数量的倍数,否则可能因 GPGPU 负载不均衡而引发性能问题。出现此类情况时,STAR-CCM+ 将在命令行发出警告信息。 -
若使用 NVIDIA GPU 且指定的 CPU 进程数超过主机上使用的 GPGPU 卡数量,则必须启用 CUDA Multi-Process Service (MPS)。该服务默认处于调用状态。
下表所示为在单张 GPU 卡上运行 500 万单元、恒定密度的管道流动仿真(采用双方程湍流模型)的内存使用情况:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3 启用GPU计算
可从工作空间或命令行定义 GPGPU 使用方式。
从工作空间启动启用 GPGPU 的仿真:
-
启动工作空间。
-
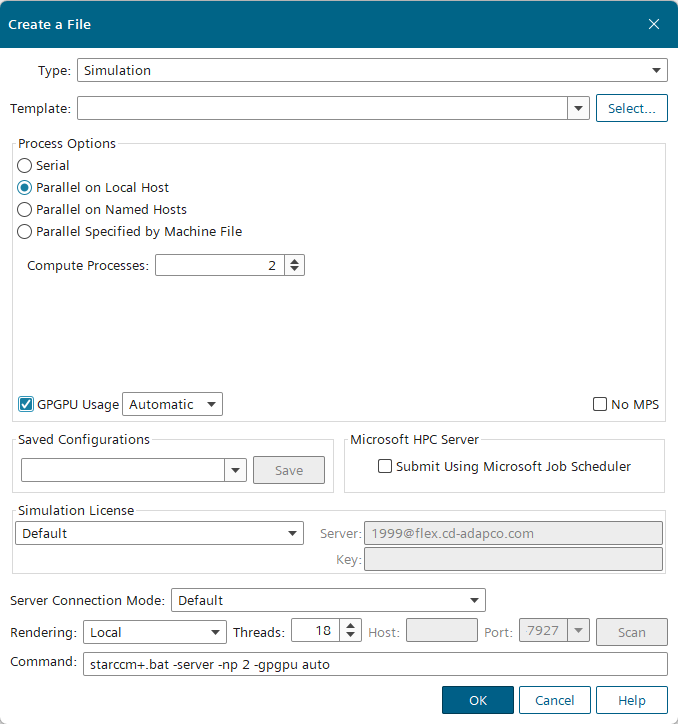
若启动新仿真,选择 File > New... 以激活 Create a File对话框。 -
若打开现有仿真,选择 File > Load... 以激活 Load a File对话框。 -
指定仿真的 CPU 进程数。
-
若在单个 CPU 上运行仿真,选择 Serial 进程选项(默认)。 -
若在多个 CPU 上并行运行仿真,选择 Parallel on Local Host 并在 Compute Processes 框中输入进程数。 -
启用 GPGPU Usage。
默认情况下,GPGPU Usage 选项设置为 Automatic,No MPS 选项处于禁用状态。
-
使用以下 GPGPU 使用选项之一,从本地机器可用的 GPGPU 中进行选择:
选择 GPGPU 后,用于启动服务器的等效命令行将显示在 Command 文本框中。
-
Automatic(默认) -
Count -
Specific -
File (Linux only) -
完成对话框中的其他参数配置。
-
设置仿真物理模型时,确保仅选择与 GPGPU 兼容的求解器和模型。
(完)

本篇文章来源于微信公众号: CFD之道







评论前必须登录!
注册