深度强化学习,简称强化学习(RL),是深度学习领域中的一类方法,它使得人工智能代理能够探索与周围环境的交互。在此过程中,代理接收其行为的奖励信号,并尝试确定哪些行为有助于获得更高的奖励,以相应地调整其行为。RL已经在玩围棋等游戏方面取得了很大成功{cite}silver2017mastering,并为机器人等工程应用带来了希望。
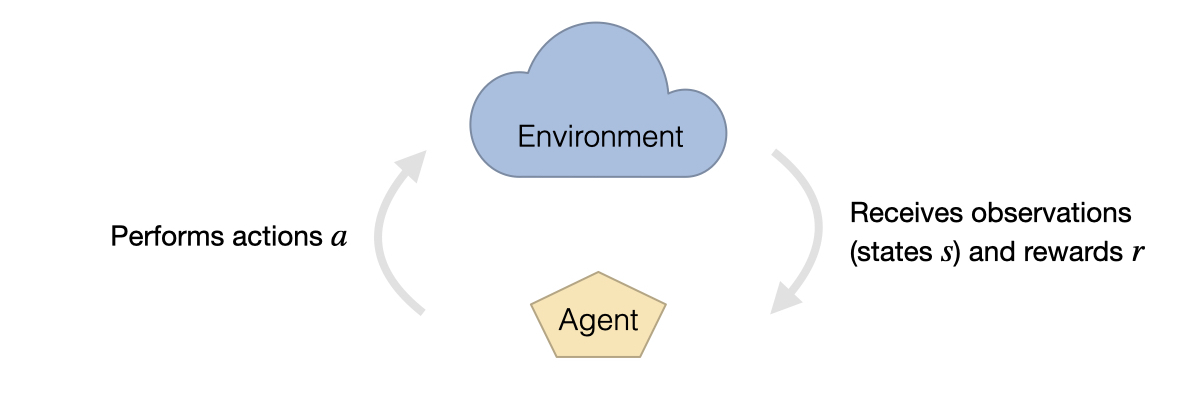
强化学习的设置通常由两部分组成:环境和代理。环境接收代理的动作,同时以状态和奖励的形式提供观察结果。观察结果表示代理能够感知的环境状态信息的一部分。奖励由预定义的函数给出,通常是针对环境进行定制的,并可能包含游戏得分、错误动作的惩罚或成功完成任务的奖励等内容。
简单来说, 强化学习任务的学习目标可以表示为:
在这里,时刻的奖励(上面表示为)是由代理执行的动作的结果。代理根据神经网络策略选择它们的动作,这个策略通过一组给定的观察结果来决定。策略返回动作的概率,并且是基于环境状态和权重的条件概率。
在学习过程中,强化学习的中心目标是利用状态、动作和相应的奖励的综合信息,增加每条轨迹上奖励信号的累积强度。为了实现这个目标,提出了多种算法,可以大致分为两类:策略梯度和基于价值的方法(参见[Sutton and Barto, 2018])。
15.1 算法
在普通的策略梯度方法中,训练好的神经网络直接从环境观测中选择动作。在学习过程中,神经网络被训练用于推断动作的概率。在这里,导致剩余轨迹中获得更高回报的动作的概率会增加,而回报较小的动作则会变得不太可能。
另一方面,基于价值的方法,如_Q-Learning_,通过优化状态-动作值函数,即所谓的_Q函数_来工作。在这种情况下,网络接收状态和动作,以预测从该输入产生的剩余轨迹的平均累积奖励,即。然后根据状态选择最大化的动作。
此外,_演员-评论家_方法结合了两种方法的元素。在这里,策略网络生成的动作会根据相应状态潜力的变化进行评估。这些值由另一个神经网络给出,并近似于给定状态的预期累积奖励。近端策略优化(Proximal policy optimization,PPO){cite}schulman2017proximal是这类算法中的一个例子,也是本章示例任务(将Burgers方程作为物理环境进行控制)的选择。

15.2 近端策略优化
由于PPO方法是一种演员-评论家方法,我们需要训练两个相互依赖的网络:演员和评论家。
演员的目标本质上依赖于评论家网络的输出(它提供了哪些行动值得执行的反馈),反之评论家依赖于演员网络生成的行动(这决定了要探索哪些状态)。
这种相互依赖关系可能会促进不稳定性,例如,强烈的过度或低估的状态值可能会在学习过程中给出错误的冲动。产生更高奖励的行动通常也有助于达到具有更高信息价值的状态。因此,当允许个别样本的可能不正确的价值估计无限制地影响代理的行为时,学习进展可能会崩溃。
PPO被引入作为一种特别对抗这个问题的方法。其想法是限制个别状态价值估计对演员行为变化在学习过程中的影响。PPO在处理连续行动空间时是一个流行的选择。这可以归因于它倾向于实现良好的结果和稳定的学习进展,同时仍然相对容易实现。
15.2.1 PPO-clip
更具体地说,我们将使用算法_PPO-clip_ {cite}“schulman2017proximal”。这种PPO变体为由单个更新步骤引起的行为变化设置了硬限制。因此,该算法使用先前的网络状态(在下面用下标表示)来限制学习过程中每步的变化。在接下来的内容中,我们将把演员网络的网络参数表示为,批评家的网络参数表示为。
15.2.2 Actor
该演员计算一个策略函数,返回在当前网络参数和状态条件下行动的概率分布。
在接下来的内容中,我们将用表示从分布中选择特定动作的概率。如上所述,训练过程使用固定的先前网络状态进行策略评估,计算一定数量的权重更新,并在间隔中重新初始化先前的权重为。为了限制变化,目标函数使用函数,简单地返回被夹在区间内。
定义了与先前策略的偏差界限。结合起来,演员的目标函数由以下表达式给出:
由于演员网络被训练为提供期望值,在训练时会使用额外的标准差从高斯分布中采样值,围绕这个均值。随着训练的进行,标准差逐渐减小,在推理时我们只评估均值(即方差为0的分布)。
15.2.3 评论家和优势
评论家由值函数表示,该函数预测从状态获得的预期累积奖励。
它的目标是最小化平方优势。
优势函数基于,其目标是评估累积奖励平均值的偏差。也就是说,我们有兴趣估计通过做出的决策在多大程度上改善了随机决策(再次通过不变的先前网络状态进行评估)。我们使用所谓的广义优势估计(GAE){cite}schulman2015high来计算:
这里的表示在时间步获得的奖励,表示轨迹的总长度。和是两个超参数,它们影响从远期对奖励和状态值预测对优势计算的影响。它们通常被设置为小于1的值。
上述公式中的表示对真实优势的有偏估计。因此,GAE可以理解为从当前时间步到轨迹结束的这些估计的折现累积和。
15.3 在反问题中的应用
强化学习广泛应用于多个决策问题构建的轨迹优化。然而,在物理系统和偏微分方程的背景下,强化学习算法同样具有吸引力。在这种情况下,它们可以通过生成完整轨迹并通过将最终逼近与目标进行比较来操作,类似于监督单射击方法。
然而,这些方法在优化方式上存在差异。例如,像PPO这样的强化学习算法尝试通过将随机偏移量添加到演员选择的动作中来在训练过程中探索行动空间。这样,算法可以发现比以前更精细的新行为模式。
生成的力的长期效应如何被考虑也可以因物理系统而异。在具有可微分物理(DP)损失的控制力估计器设置中,如在{doc}diffphys-code-burgers中讨论的那样,这些依赖关系通过将损失梯度通过仿真步骤传递回以前的时间步来处理。相反,强化学习通常将环境视为没有梯度信息的黑盒子。当使用PPO时,值估计器网络被用来通过预测任何动作对未来系统演变的影响来跟踪长期依赖关系。
在以Burgers方程为物理环境的情况下,轨迹生成过程可以总结如下。它展示了环境的仿真步骤和代理的神经网络评估是如何交错的:
上标(通常)表示参考或目标量,因此这里表示速度目标。对于PDE的连续动作空间,直接计算一个力的动作,而不是一组不同动作概率的离散集合。
奖励的计算方式与DP方法中的损失类似:它由两部分组成,其中一部分相当于应用力的负平方范数,并在每个时间步骤给出。另一部分添加了一个惩罚,该惩罚与每个轨迹结束时的最终逼近和目标状态之间的距离成比例。

15.4 实现
下面,我们将描述一种实现基于PPO的物理系统RL训练的方法。这个实现也是下一节笔记本{doc}reinflearn-code的基础。虽然这个笔记本提供了一个实际的例子,并与DP训练进行了比较,但我们首先会在下面给出一个更通用的概述。
为了训练一个强化学习代理来控制一个PDE-governed系统,物理模型必须被形式化为一个RL环境。我们在接下来使用的stable-baselines3框架中,使用了一个向量化版本的OpenAI gym环境来实现PPO训练。这样,可以并行地在多个轨迹上进行回滚收集,以更好地利用资源和提高时间效率。向量化环境需要定义观察和动作空间,即代理策略的输入和输出空间。在我们的情况下,前者包括当前物理状态和目标状态,例如速度场,沿着它们的通道维度堆叠。另外一个通道添加了自模拟开始以来经过的时间除以总轨迹长度。动作空间(输出)包括速度场每个单元格的一个力值。
向量化环境中最相关的方法是reset、step_async、step_wait和render。其中,reset用于通过计算初始状态和目标状态并返回每个向量化实例的第一个观测来启动新轨迹。由于这些实例在其他应用程序中不必同步完成轨迹,reset必须在进入终止状态时从环境内部调用。 step_async和step_wait是step方法的两个主要部分,该方法采取行动,将其应用于速度场并执行物理模型的一次迭代。异步和等待的分割使支持在单独的线程上运行每个实例的向量化环境成为可能。但是,在我们的方法中并不需要这样做,因为phiflow在内部处理批次的模拟。调用render方法以显示训练结果,实时显示重构的轨迹或将其呈现到文件中。
由于演员和评论家网络的输出空间差异很大,我们为每个网络使用不同的体系结构。生成行动的网络使用Holl等人的网络体系结构的变体,与那里执行行动的函数一致。另一个网络由一系列内核大小为3的卷积组成,每个卷积后跟一个内核大小为2且步幅为2的最大池化层。在这种方式下采样特征图至一个值后,最终的全连接层合并所有通道,生成预测状态值。
在下一章的示例实现中,BurgersTraining类在内部管理此培训的所有方面,包括代理和环境的设置,并将训练模型和监视日志存储到磁盘。它还包括上述Burgers方程环境的变体,该环境使用预定义集合中的数据,而不是计算随机轨迹。在训练期间,代理在此环境中进行评估,以便能够更准确地将训练进度与DP方法进行比较。
下一章将使用此BurgersTraining类来运行完整的PPO场景,评估其性能,并将其与使用物理系统更多领域知识的方法进行比较,即基于梯度的控制培训与DP方法。